Testing with FSharp.Stats I: t-test¶
Getting started: The t-test¶
I love statistical testing - A sentence math teachers don't hear often during their time at school. In this tutorial we aim to give you a short introduction of the theory and how to perform the most used statistical test: the t-test
Suppose you have measured the length of some leaves of two trees and you want to find out if the average length of the leaves is the same or if they differ from each other. If you knew the population distributions of all leaves hanging on both trees the task would be easy, but since we only have samples from both populations, we have to apply a statistical test. Student's t-test can be applied to test whether two samples have the same mean (H0), or if the means are different (H1). There are two requirements to the samples that have to be fulfilled:
The variances of both samples have to be equal.
The samples have to follow a normal distribution.
Note: Slight deviations from these requirements can be accepted but strong violations result in an inflated false positive rate. If the variances are not equal a Welch test can be performed. There are some tests out there to check if the variances are equal or if the sample follows a normal distribution, but their effectiveness is discussed. You always should consider the shape of the theoretical background distribution, instead of relying on preliminary tests rashly.
The t-test is one of the most used statistical tests in datascience. It is used to compare two samples in terms of statistical significance. Often a significance threshold (or α level) of 0.05 is chosen to define if a p value is defined as statistically significant. A p value describes how likely it is to observe an effect at least as extreme as you observed (in the comparison) by chance. Low p values indicate a high confidence to state that there is a real difference and the observed difference is not caused by chance.
In [3]:
#r "nuget: Deedle.Interactive, 3.0.0"
#r "nuget: FSharp.Stats, 0.4.3"
#r "nuget: Plotly.NET.Interactive, 4.0.0"
#r "nuget: FSharp.Data, 4.2.7"
open FSharp.Data
open Deedle
open Plotly.NET
Installed Packages
- Deedle.Interactive, 3.0.0
- FSharp.Data, 4.2.7
- FSharp.Stats, 0.4.3
- Plotly.NET.Interactive, 4.0.0
For our purposes, we will use the housefly wing length dataset (from Sokal et al., 1955, A morphometric analysis of DDT-resistant and non-resistant housefly strains). Head over to the Getting started tutorial where it is shown how to import datasets in a simple way.
In [4]:
// We retrieve the dataset via FSharp.Data:
let rawDataHousefly = Http.RequestString @"https://raw.githubusercontent.com/fslaborg/datasets/main/data/HouseflyWingLength.txt"
let dataHousefly : seq<float> =
Frame.ReadCsvString(rawDataHousefly, false, schema = "wing length (mm * 10^1)")
|> Frame.getCol "wing length (mm * 10^1)"
|> Series.values
// We convert the values to mm
|> Seq.map (fun x -> x / 10.)
Let us first have a look at the sample data with help of a boxplot. As shown below, the average wingspan is around 4.5 with variability ranges between 3.5 and 5.5.
In [6]:
Chart.BoxPlot(
Y = dataHousefly,
Name = "housefly",
BoxPoints = StyleParam.BoxPoints.All,
Jitter = 0.2
)
|> Chart.withYAxisStyle "wing length [mm]"
One-sample t-test¶
We want to analyze if an estimated expected value differs from the sample above. Therefore, we perform a one-sample t-test which covers exactly this situation.
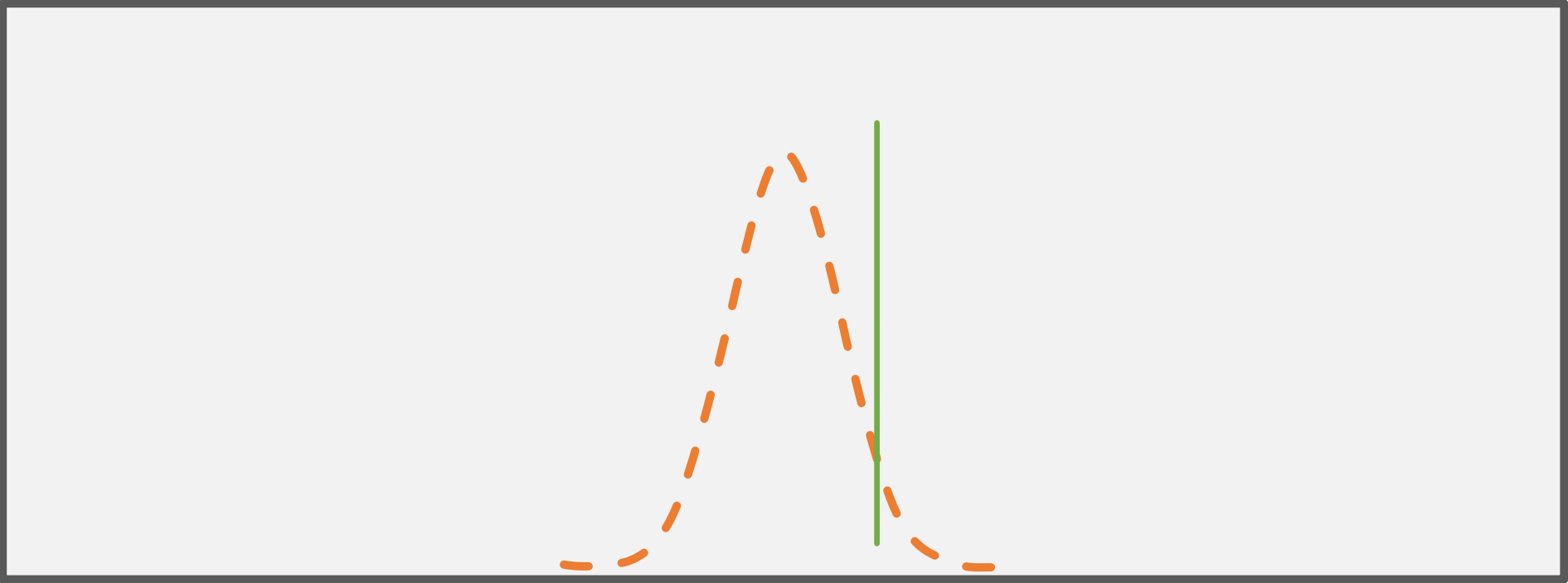
Fig. 1: The one-sample t-test The dashed orange line depicts the distribution of our sample, the green bar the expected value to test against.
In [7]:
open FSharp.Stats
open FSharp.Stats.Testing
// The testing module in FSharp.Stats require vectors as input types, thus we transform our array into a vector:
let vectorDataHousefly = vector dataHousefly
// The expected value of our population.
let expectedValue = 4.5
// Perform the one-sample t-test with our vectorized data and our exptected value as parameters.
let oneSampleResult = TTest.oneSample vectorDataHousefly expectedValue
oneSampleResult
{ Statistic = 1.275624919\n DegreesOfFreedom = 99.0\n PValueLeft = 0.8974634108\n PValueRight = 0.1025365892\n PValue = 0.2050731784 }
| Statistic | 1.2756249193674383 |
| DegreesOfFreedom | 99 |
| PValueLeft | 0.8974634107766597 |
| PValueRight | 0.1025365892233403 |
| PValue | 0.2050731784466806 |
The function returns a TTestStatistics type. If contains the fields
Statistic: defines the exact teststatisticDegreesOfFreedom: defines the degrees of freedomPValueLeft: the left-tailed p-valuePValueRight: the right-tailed p-valuePValue: the two-tailed p-value
As we can see, when looking at the two-tailed p-value, our sample does not differ significantly from our expected value. This matches our visual impression of the boxplot, where the sample distribution is centered around 4.5.
Two-sample t-test (unpaired data)¶
The t-test is most often used in its two-sample variant. Here, two samples, independent from each other, are compared. It is required that both samples are normally distributed. In this next example, we are going to see if the gender of college athletes determines the number of concussions suffered over 3 years (from: Covassin et al., 2003, Sex Differences and the Incidence of Concussions Among Collegiate Athletes, Journal of Athletic Training).
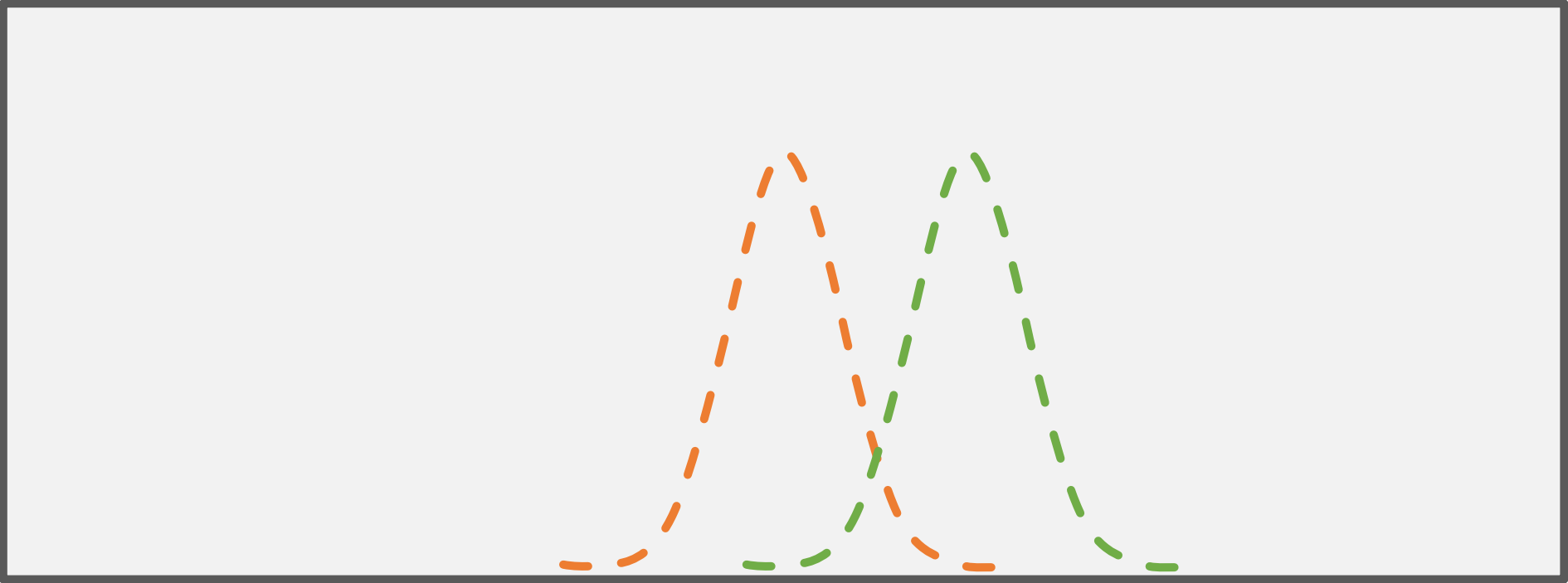
Fig. 2: The two-sample t-test The dashed orange and green lines depict the distribution of both samples that are compared with each other.
In [9]:
open System.Text
let rawDataAthletes = Http.RequestString @"https://raw.githubusercontent.com/fslaborg/datasets/main/data/ConcussionsInMaleAndFemaleCollegeAthletes_adapted.tsv"
let dataAthletesAsStream = new System.IO.MemoryStream(rawDataAthletes |> Encoding.UTF8.GetBytes)
// The schema helps us setting column keys.
let dataAthletesAsFrame = Frame.ReadCsv(dataAthletesAsStream, hasHeaders = false, separators = "\t", schema = "Gender, Sports, Year, Concussion, Count")
dataAthletesAsFrame
| Gender | Sports | Year | Concussion | Count | (string) | (string) | (int) | (Boolean) | (int) |
|---|---|---|---|---|---|---|
| 0 | -> | Female | Soccer | 1997 | False | 24930 |
| 1 | -> | Female | Soccer | 1997 | True | 51 |
| 2 | -> | Female | Soccer | 1998 | False | 22887 |
| 3 | -> | Female | Soccer | 1998 | True | 47 |
| 4 | -> | Female | Soccer | 1999 | False | 27107 |
| : | ... | ... | ... | ... | ... | |
| 55 | -> | Male | Gymnastics | 1997 | True | 0 |
| 56 | -> | Male | Gymnastics | 1998 | False | 221 |
| 57 | -> | Male | Gymnastics | 1998 | True | 0 |
| 58 | -> | Male | Gymnastics | 1999 | False | 1179 |
| 59 | -> | Male | Gymnastics | 1999 | True | 0 |
60 rows x 5 columns
0 missing values
In [10]:
// We need to filter out the columns and rows we don't need. Thus, we filter out the rows where the athletes suffered no concussions
// as well as filter out the columns without the number of concussions.
let dataAthletesFemale, dataAthletesMale =
let getAthleteGenderData gender =
let dataAthletesOnlyConcussion =
dataAthletesAsFrame
|> Frame.filterRows (fun r objS -> objS.GetAs "Concussion")
let dataAthletesGenderFrame =
dataAthletesOnlyConcussion
|> Frame.filterRows (fun r objS -> objS.GetAs "Gender" = gender)
dataAthletesGenderFrame
|> Frame.getCol "Count"
|> Series.values
|> vector
getAthleteGenderData "Female", getAthleteGenderData "Male"
Again, let's check our data via boxplots before we proceed on comparing them.
In [12]:
[
Chart.BoxPlot(Y = dataAthletesFemale, Name = "female college athletes", BoxPoints = StyleParam.BoxPoints.All, Jitter = 0.2)
Chart.BoxPlot(Y = dataAthletesMale, Name = "male college athletes", BoxPoints = StyleParam.BoxPoints.All, Jitter = 0.2)
]
|> Chart.combine
|> Chart.withYAxisStyle "number of concussions over 3 years"
Both samples are tested against using FSharp.Stats.Testing.TTest.twoSample and assuming equal variances.
In [13]:
// We test both samples against each other, assuming equal variances.
let twoSampleResult = TTest.twoSample true dataAthletesFemale dataAthletesMale
twoSampleResult
{ Statistic = 0.5616104016\n DegreesOfFreedom = 28.0\n PValueLeft = 0.7105752703\n PValueRight = 0.2894247297\n PValue = 0.5788494593 }
| Statistic | 0.56161040164984 |
| DegreesOfFreedom | 28 |
| PValueLeft | 0.7105752703384163 |
| PValueRight | 0.2894247296615837 |
| PValue | 0.5788494593231674 |
With a p value of 0.58 the t-test indicate that there's no significant difference between the number of concussions over 3 years between male and female college athletes.
Two-sample t-test (paired data)¶
Paired data describes data where each value from the one sample is connected with its respective value from the other sample.
In the next case, the endurance performance of several persons in a normal situation (control situation) is compared to their performance after ingesting a specific amount of caffeine*.
It is the same person that performs the exercise but under different conditions. Thus, the resulting values of the persons under each condition are compared.
Another example are time-dependent experiments: One measures, e.g., the condition of cells stressed with a high surrounding temperature in the beginning and after 30 minutes.
The measured cells are always the same, yet their conditions might differ.
Due to the connectivity of the sample pairs the samples must be of equal length.
*Source: W.J. Pasman, M.A. van Baak, A.E. Jeukendrup, A. de Haan (1995). The Effect of Different Dosages of Caffeine on Endurance Performance Time, International Journal of Sports Medicine, Vol. 16, pp225-230.
In [14]:
let rawDataCaffeine = Http.RequestString @"https://raw.githubusercontent.com/fslaborg/datasets/main/data/CaffeineAndEndurance(wide)_adapted.tsv"
let dataCaffeineAsStream = new System.IO.MemoryStream(rawDataCaffeine |> Encoding.UTF8.GetBytes)
let dataCaffeineAsFrame = Frame.ReadCsv(dataCaffeineAsStream, hasHeaders = false, separators = "\t", schema = "Subject ID, no Dose, 5 mg, 9 mg, 13 mg")
// We want to compare the subjects' performances under the influence of 13 mg caffeine and in the control situation.
let dataCaffeineNoDose, dataCaffeine13mg =
let getVectorFromCol col =
dataCaffeineAsFrame
|> Frame.getCol col
|> Series.values
|> vector
getVectorFromCol "no Dose", getVectorFromCol "13 mg"
// Transforming our data into a chart.
Seq.zip dataCaffeineNoDose dataCaffeine13mg
|> Seq.mapi (fun i (control,treatment) ->
let participant = "Person " + string i
Chart.Line(["no dose", control; "13 mg", treatment], Name = participant)
)
|> Chart.combine
|> Chart.withXAxisStyle ""
|> Chart.withYAxisStyle("endurance performance", MinMax = (0.,100.))
The function for pairwise t-tests can be found at FSharp.Stats.Testing.TTest.twoSamplePaired. Note, that the order of the elements in each vector must be the same, so that a pairwise comparison can be performed.
In [15]:
let twoSamplePairedResult = TTest.twoSamplePaired dataCaffeineNoDose dataCaffeine13mg
twoSamplePairedResult
{ Statistic = 3.252507672\n DegreesOfFreedom = 8.0\n PValueLeft = 0.9941713794\n PValueRight = 0.005828620625\n PValue = 0.01165724125 }
| Statistic | 3.2525076715666534 |
| DegreesOfFreedom | 8 |
| PValueLeft | 0.9941713793753144 |
| PValueRight | 0.005828620624685588 |
| PValue | 0.011657241249371175 |
The two-sample paired t-test suggests a significant difference beween caffeine and non-caffeine treatment groups with a p-value of 0.012.