Multiple testing correction: q values¶
TLDR: A q value defines the proportion of false positives there are within all discoveries that were called significant up to the current item.
Getting started: Multiple testing problem¶
High throughput techniques like microarrays with its successor RNA-Seq and mass spectrometry proteomics lead to an huge data amount. Thousands of features (e.g. transcripts or proteins) are measured simultaneously. Differential expression analysis aims to identify features, that change significantly between two conditions. A common experimental setup is the analysis of which genes are over- or underexpressed between e.g. a wild type and a mutant.
Hypothesis tests aim to identify differences between two or more samples. The most common statistical test is the t test that tests a difference of means. Hypothesis tests report a p value, that correspond the probability of obtaining results at least as extreme as the observed results, assuming that the null hypothesis is correct. In other words:
Referencing packages¶
In [1]:
// required for auxiliary functions
#r "nuget: FSharpAux, 2.0.0"
// required for all calculations
#r "nuget: FSharp.Stats, 0.6.0"
// required to read the pvalue set
#r "nuget: FSharp.Data, 4.2.7"
// required for charting
#r "nuget: Plotly.NET.Interactive, 5.0.0"
open FSharpAux
open FSharp.Stats
open FSharp.Data
open Plotly.NET
open Plotly.NET.StyleParam
open Plotly.NET.LayoutObjects
Installed Packages
- FSharp.Data, 4.2.7
- FSharp.Stats, 0.6.0
- FSharpAux, 2.0.0
- Plotly.NET.Interactive, 5.0.0
Loading extensions from `C:\Users\bvenn\.nuget\packages\plotly.net.interactive\5.0.0\lib\netstandard2.1\Plotly.NET.Interactive.dll`
Consider two population distributions that follow a normal distribution. Both have the same mean and standard deviation.
In [2]:
let distributionA = Distributions.Continuous.Normal.Init 10.0 1.0
let distributionB = Distributions.Continuous.Normal.Init 10.0 1.0
let distributionChartAB =
[
Chart.Area(xy = ([5. .. 0.01 .. 15.] |> List.map (fun x -> x,distributionA.PDF x)), Name = "distA")
Chart.Area(xy = ([5. .. 0.01 .. 15.] |> List.map (fun x -> x,distributionB.PDF x)), Name = "distB")
]
|> Chart.combine
|> Chart.withTemplate ChartTemplates.lightMirrored
|> Chart.withXAxisStyle "variable X"
|> Chart.withYAxisStyle "relative count"
|> Chart.withSize (900.,600.)
|> Chart.withTitle "null hypothesis"
distributionChartAB
Samples with sample size 5 are randomly drawn from both population distributions. Both samples are tested if a mean difference exist using a two sample t test where equal variances of the underlying population distribution are assumed.
In [3]:
let getSample n (dist: Distributions.ContinuousDistribution<float,float>) =
Vector.init n (fun _ -> dist.Sample())
let sampleA = getSample 5 distributionA
let sampleB = getSample 5 distributionB
let pValue = (Testing.TTest.twoSample true sampleA sampleB).PValue
pValue
0.3659784597826854
10,000 tests are performed, each with new randomly drawn samples. This corresponds to an experiment in which none of the features changed. Note, that the mean intensities are arbitrary and must not be the same for all features! In the presented case all feature intensities are in average 10. The same simulation can be performed with pairwise comparisons from distributions that differ for each feature, but are the same within the feature. The resulting p values are uniformly distributed between 0 and 1.
In [ ]:
/// Calculates the p-value for samples from two distributions with a given sampleSize.
let calcPValue (distributionA: Distributions.ContinuousDistribution<float,float>) distributionB (sampleSize: int) =
let sampleA = getSample sampleSize distributionA
let sampleB = getSample sampleSize distributionB
(Testing.TTest.twoSample true sampleA sampleB).PValue
/// Collection of 10k performed t-tests with samples drawn from distA and distB (identical distribution).
let pVals_identical =
Array.init 10_000 (fun _ -> calcPValue distributionA distributionB 5)
// Creates a histogram of the p-values from the t-tests
// and highlights the area of p-values below 0.05 using a rectangle shape and an annotation.
Chart.Histogram(pVals_identical, XBins = TraceObjects.Bins.init(0., 1., 0.025))
|> Chart.withTemplate ChartTemplates.lightMirrored
|> Chart.withXAxisStyle "p value"
|> Chart.withYAxisStyle "frequency"
|> Chart.withTitle "p value distribution of the null hypothesis<br>10,000 t-tests of samples from the same distribution"
|> Chart.withShape(
Shape.init(
ShapeType = StyleParam.ShapeType.Rectangle,
X0 = 0.0,
X1 = 0.05,
Y0 = 0.,
Y1 = 280.,
Line = Line.init(Color = Color.fromHex "c00000", Width = 2)
)
)
|> Chart.withAnnotation(
Annotation.init(
Text = "p < 0.05<br>= 5% false positives",
X = 0.03,
Y = 283.,
ShowArrow = true,
Font = Font.init(Size = 16),
BGColor = Color.fromString "white",
AX=90.,
AY=(-80.)
)
)
|> Chart.withSize (900.,600.)
Samples are called significantly different, if their p value is below a certain significance threshold ($\alpha$ level). While "the lower the better", a common threshold is a p value of 0.05 or 0.01. In the presented case in average $10,000 * 0.05 = 500$ tests are significant (red box), even though the populations do not differ. They are called false positives (FP). Now lets repeat the same experiment, but this time sample 70% of the time from null features (no difference) and add 30% samples of truly differing distributions. Therefore a third populations is generated, that differ in mean, but has an equal standard deviation:
In [5]:
let distributionC = Distributions.Continuous.Normal.Init 11.5 1.0
let distributionChartAC =
[
Chart.Area(xy = ([5. .. 0.01 .. 15.] |> List.map (fun x -> x,distributionA.PDF x)), Name = "Distribution A")
Chart.Area(xy = ([5. .. 0.01 .. 15.] |> List.map (fun x -> x,distributionC.PDF x)), Name = "Distribution C")
]
|> Chart.combine
|> Chart.withLegendAnchor 1
|> Chart.withTemplate ChartTemplates.lightMirrored
|> Chart.withXAxisStyle "variable X"
|> Chart.withYAxisStyle "density"
let pvals_null =
Array.init 7000 (fun _ -> calcPValue distributionA distributionB 5)
|> fun x -> Distributions.EmpiricalDistribution.create 0.025 x
|> Map.toArray |> Array.map (fun (a,b) -> a, b*7000.)
let pvals_alternative =
Array.init 3000 (fun _ -> calcPValue distributionA distributionC 5)
|> fun x -> Distributions.EmpiricalDistribution.create 0.025 x
|> Map.toArray |> Array.map (fun (a,b) -> a, b*3000.)
let histo_alternative =
[
Chart.StackedColumn(pvals_null, Name = "70 % null tests")
Chart.StackedColumn(pvals_alternative, Name = "30 % with true effect")
]
|> Chart.combine
|> Chart.withLegendAnchor 2 // define legend id to separately move this legend down
|> Chart.withTemplate ChartTemplates.lightMirrored
|> Chart.withXAxisStyle "p value"
|> Chart.withYAxisStyle "frequency"
[distributionChartAC;histo_alternative]
|> Chart.Grid(2,1)
|> Chart.withSize (1000.,900.)
|> Chart.withTitle "alternative hypothesis"
|> Chart.withLegend(Legend.init(Y = 0.30),Id = 2) // move legend of lower panel down
|> Chart.withAnnotations [
Annotation.init(
Text = "10,000<br>t tests",
X = 1.2,
Y = 0.5,
XRef = "paper",
YRef = "paper",
ShowArrow = false,
TextAngle = 270.
)
Annotation.init(
Text = "effect",
X = 0.115,
Y = 400,
AX = 30.,
AY = -30.,
ShowArrow = true,
Font = Font.init(Family= FontFamily.Droid_Serif, Size = 16),
XRef = "x2",
YRef = "y2"
)
]
|> Chart.withShape(
Shape.init(
ShapeType = StyleParam.ShapeType.SvgPath,
// path can be generated or edited at https://yqnn.github.io/svg-path-editor/
Path = "M 1.035 0.6025 C 1.11 0.5525 1.11 0.4525 1.0379 0.4005 L 1.053 0.3834 L 1.0115 0.3846 L 1.0122 0.4286 L 1.0272 0.4118 C 1.0605 0.4381 1.1146 0.5173 1.0279 0.5908 L 1.035 0.6025",
Xref = "paper",
Yref = "paper",
FillColor = Color.fromHex "515151"
)
)
Fig 2: p value distribution of the alternative hypothesis. Blue coloring indicate p values deriving from distribution A and B (null). Orange coloring indicate p values deriving from distribution A and C (truly differing).
The pvalue distribution of the tests resulting from truly differing populations are right skewed, while the null tests again show a homogeneous distribution between 0 and 1. Many, but not all of the tests that come from the truly differing populations are below 0.05, and therefore would be reported as significant. In average 350 null features would be reported as significant even though they derive from null features (blue bars, 10,000 x 0.7 x 0.05 = 350).
The multiple testing problem¶
The hypothesis testing framework with the p value definition given above was developed for performing just one test. If many tests are performed, like in modern high throughput studies, the probability to obtain a false positive result increases. The probability of at least one false positive is called Familywise error rate (FWER) and can be determined by $FWER=1-(1-\alpha)^m$ where $\alpha$ corresponds to the significance threshold (here 0.05) and $m$ is the number of performed tests.
In [6]:
let bonferroniLine =
Shape.init(ShapeType=ShapeType.Line,X0=0.,X1=35.,Y0=0.05,Y1=0.05,Line=Line.init(Dash=DrawingStyle.Dash))
let fwer =
[1..35]
|> List.map (fun x ->
x,(1. - (1. - 0.05)**(float x))
)
|> Chart.Point
|> Chart.withTemplate ChartTemplates.lightMirrored
|> Chart.withXAxisStyle "#tests"
|> Chart.withYAxisStyle("p(at least one FP)",MinMax=(0.,1.))
|> Chart.withShape bonferroniLine
|> Chart.withTitle "FWER"
fwer
Fig 3: Family wise error rate depending on number of performed tests. The black dashed line indicates the Bonferroni corrected FWER by $p^* = \frac{\alpha}{m}$ .
When 10,000 null features are tested with a p value threshold of 0.05, in average 500 tests are reported significant even if there is not a single comparisons in which the population differ. If some of the features are in fact different, the number of false positives consequently decreases (remember, the p value is defined for tests of null features).
Why the interpretation of high throughput data based on p values is difficult: The more features are measured, the more false positives you can expect. If 100 differentially expressed genes are identified by p value thresholding, without further information about the magnitude of expected changes and the total number of measured transcripts, the data is useless.
The p value threshold has no straight-forward interpretation when many tests are performed. Of course you could restrict the family wise error rate to 0.05, regardless how many tests are performed. This is realized by dividing the $\alpha$ significance threshold by the number of tests, which is known as Bonferroni correction: $p^* = \frac{\alpha}{m}$. This correction drastically limit the false positive rate, but in an experiment with a huge count of expected changes, it additionally would result in many false negatives. The FWER should be chosen if the costs of follow up studies to tests the candidates are dramatic or there is a huge waste of time to potentially study false positives.
False discovery rate¶
A more reasonable measure of significance with a simple interpretation is the so called false discovery rate (FDR). It describes the rate of expected false positives within the overall reported significant features. The goal is to identify as many sig. features as possible while incurring a relatively low proportion of false positives. Consequently a set of reported significant features together with the FDR describes the confidence of this set, without the requirement to somehow incorporate the uncertainty that is introduced by the total number of tests performed. In the simulated case of 7,000 null tests and 3,000 tests resulting from truly differing distributions above, the FDR can be calculated exactly. Therefore at e.g. a p value of 0.05 the number of false positives (blue in red box) are divided by the number of significant reported tests (false positives + true positives).
In [7]:
histo_alternative
|> Chart.withShapes [
Shape.init(
ShapeType = StyleParam.ShapeType.Rectangle,
X0 = 0.0,
X1 = 0.05,
Y0 = 0.00,
Y1 = 184,
Line = Line.init(Color=Color.fromHex "c00000", Width = 2),
Label = ShapeLabel.init(Text="FP",Font = Font.init(Color=Color.fromHex "c00000", Size = 16))
)
Shape.init(
ShapeType = StyleParam.ShapeType.Rectangle,
X0 = 0.051,
X1 = 1.,
Y0 = 0.00,
Y1 = 184,
Line = Line.init(Color=Color.fromHex "638e48", Width = 2),
Label = ShapeLabel.init(Text="true negatives (TN)",Font = Font.init(Size = 16))
)
Shape.init(
ShapeType = StyleParam.ShapeType.Rectangle,
X0 = 0.0,
X1 = 0.05,
Y0 = 185,
Y1 = 1500,
Line = Line.init(Color=Color.fromHex "638e48", Width = 2),
Label = ShapeLabel.init(Text="TP",Font = Font.init(Size = 18))
)
Shape.init(
ShapeType = StyleParam.ShapeType.Rectangle,
X0 = 0.051,
X1 = 1.0,
Y0 = 185,
Y1 = 600,
Line = Line.init(Color=Color.fromHex "c00000", Width = 2),
Label = ShapeLabel.init(Text="false negatives (FN)",Font = Font.init(Color=Color.fromHex "c00000", Size = 16))
)
]
|> Chart.withSize(1000.,600.)
Fig 4: p value distribution of the alternative hypothesis.
Given the conditions described in the first chapter, the FDR of this experiment with a p value threshold of 0.05 is 0.173. Out of the 2019 reported significant comparisons, in average 350 are expected to be false positives, which gives an straight forward interpretation of the data confidence. In real-world experiments the proportion of null tests and tests deriving from an actual difference is of course unknown. The proportion of null tests however tends to be distributed equally in the p value histogram. By identification of the average null frequency, a proportion of FP and TP can be determined and the FDR can be defined. This frequency estimate is called $\pi_0$, which leads to an FDR definition of:
In [8]:
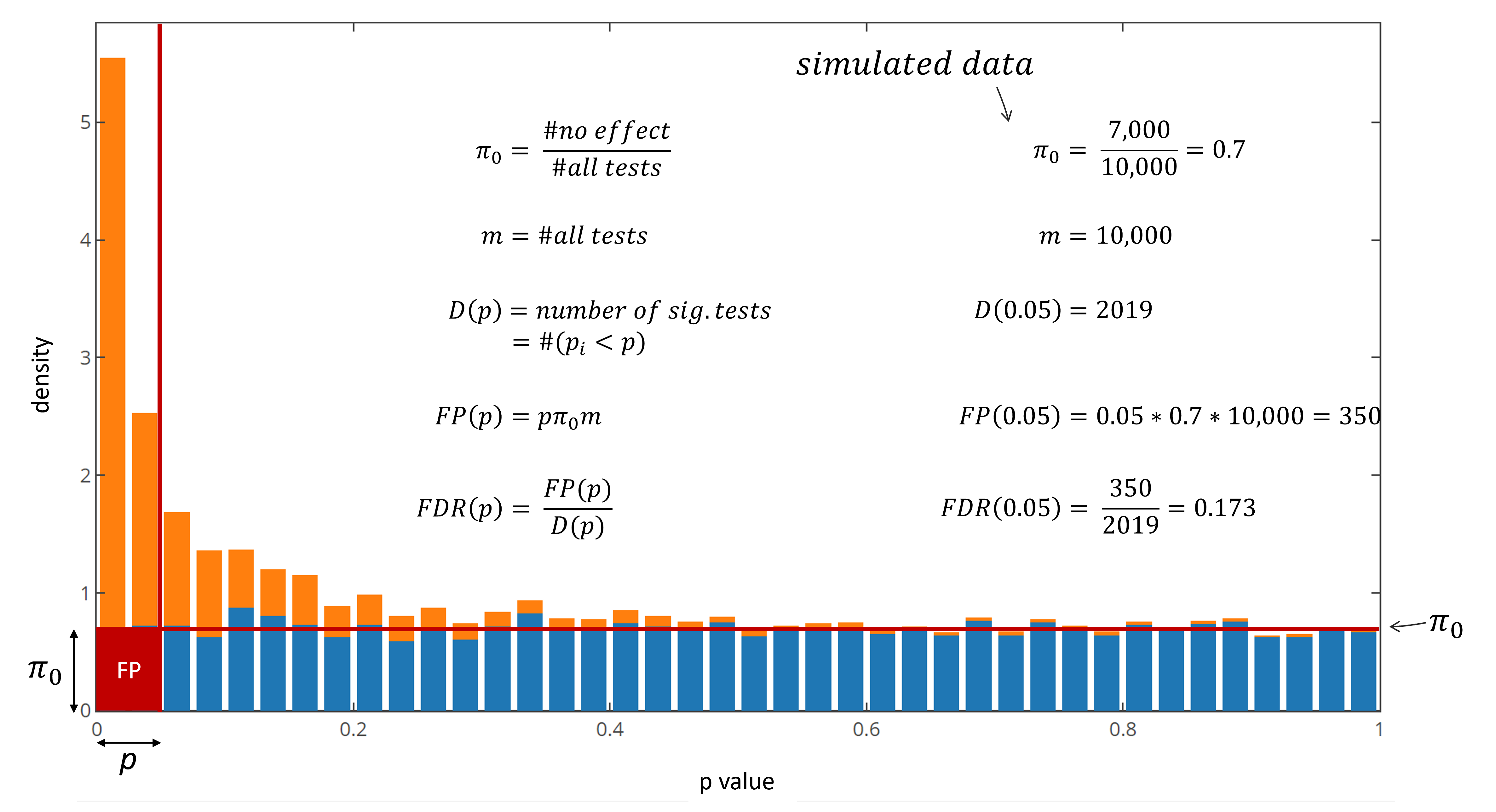
Fig 5: FDR calculation on simulated data.
q value¶
Consequently for each presented p value a corresponding FDR can be calculated. The minimum local FDR at each p value is called q value.
$$\hat q(p_i) = min_{t \geq p_i} \hat{FDR}(p_i)$$
Since the q value is not monotonically increasing, it is smoothed by assigning the lowest FDR of all p values, that are equal or higher the current one.
By defining $\pi_0$, all other parameters can be calculated from the given p value distribution to determine the all q values. The most prominent FDR-controlling method is known as Benjamini-Hochberg correction. It sets $\pi_0$ as 1, assuming that all features are null. In studies with an expected high proportion of true positives, a $\pi_0$ of 1 is too conservative, since there definitely are true positives in the data.
A better estimation of $\pi_0$ is given in the following:
True positives are assumed to be right skewed while null tests are distributed equally between 0 and 1. Consequently the right flat region of the p value histogram tends to correspond to the true frequency of null comparisons (Fig 5). As real world example 9856 genes were measured in triplicates under two conditions (control and treatment). The p value distribution of two sample t tests looks as follows:
In [9]:
let examplePVals =
let rawData = Http.RequestString @"https://raw.githubusercontent.com/fslaborg/datasets/main/data/pvalExample.txt"
rawData.Split '\n'
|> Array.tail
|> Array.map float
//number of tests
let m =
examplePVals
|> Array.length
|> float
let nullLine =
Shape.init(ShapeType=ShapeType.Line,X0=0.,X1=1.,Y0=1.,Y1=1.,Line=Line.init(Dash=DrawingStyle.Dash))
let empLine =
Shape.init(ShapeType=ShapeType.Line,X0=0.,X1=1.,Y0=0.4,Y1=0.4,Line=Line.init(Dash=DrawingStyle.DashDot,Color=Color.fromHex "#FC3E36"))
let exampleDistribution =
[
[
examplePVals
|> Distributions.Frequency.create 0.025
|> Map.toArray
|> Array.map (fun (k,c) -> k,float c / (m * 0.025))
|> Chart.Column
|> Chart.withTraceInfo "density"
|> Chart.withTemplate ChartTemplates.lightMirrored
|> Chart.withXAxisStyle "p value"
|> Chart.withYAxisStyle "density"
|> Chart.withShapes [nullLine;empLine]
examplePVals
|> Distributions.Frequency.create 0.025
|> Map.toArray
|> Array.map (fun (k,c) -> k,float c)
|> Chart.Column
|> Chart.withTraceInfo "gene count"
|> Chart.withTemplate ChartTemplates.lightMirrored
|> Chart.withXAxisStyle "p value"
|> Chart.withYAxisStyle "gene count"
]
]
|> Chart.Grid()
|> Chart.withSize(1100.,550.)
exampleDistribution
Fig 6: p value distributions of real world example. The frequency is given on the right, its density on the left. The black dashed line indicates the distribution, if all features were null. The red dash-dotted line indicates the visual estimated pi0.
By performing t tests for all comparisons 3743 (38 %) of the genes lead to a pvalue lower than 0.05. By eye, you would estimate $\pi_0$ as 0.4, indicating, only a small fraction of the genes are unaltered (null). After q value calculations, you would filter for a specific FDR (e.g. 0.05) and end up with an p value threshold of 0.04613, indicating a FDR of max. 0.05 in the final reported 3642 genes.
pi0 = 0.4
m = 9856
D(p) = number of sig. tests at given p
FP(p) = p*0.4*9856
FDR(p) = FP(p) / D(p)
FDR(0.04613) = 0.4995
Now let's compare p- to its corresponding q values with ensuring continuity
In [10]:
let pi0 = 0.4
let getD p =
examplePVals
|> Array.sumBy (fun x -> if x <= p then 1. else 0.)
let getFP p = p * pi0 * m
let getFDR p = (getFP p) / (getD p)
let qvaluesNotSmoothed =
examplePVals
|> Array.sort
|> Array.map (fun x ->
x, getFDR x)
|> Chart.Line
|> Chart.withTraceInfo "not smoothed"
let qvaluesSmoothed =
let pValsSorted =
examplePVals
|> Array.sortDescending
let rec loop i lowest acc =
if i = pValsSorted.Length then
acc |> List.rev
else
let p = pValsSorted.[i]
let q = getFDR p
if q > lowest then
loop (i+1) lowest ((p,lowest)::acc)
else loop (i+1) q ((p,q)::acc)
loop 0 1. []
|> Chart.Line
|> Chart.withTraceInfo "smoothed"
let eXpos = examplePVals |> Array.filter (fun x -> x <= 0.046135) |> Array.length
let p2qValeChart =
[qvaluesNotSmoothed;qvaluesSmoothed]
|> Chart.combine
|> Chart.withYAxisStyle("",MinMax=(0.,1.))
|> Chart.withTemplate ChartTemplates.lightMirrored
|> Chart.withXAxisStyle "p value"
|> Chart.withYAxisStyle "q value"
|> Chart.withShape empLine
|> Chart.withTitle (sprintf "#[genes with q value < 0.05] = %i" eXpos)
p2qValeChart
Fig 7: FDR calculation on experiment data. Please zoom into the very first part of the curve to inspect the monotonicity.
The automatic detection of $\pi_0$ is facilitated as follows¶
For a range of $\lambda$ in e.g. $\{0.0 .. 0.05 .. 0.95\}$, calculate $\hat \pi_0 (\lambda) = \frac {\#[p_j > \lambda]}{m(1 - \lambda)}$
In [11]:
let pi0Est =
[|0. .. 0.05 .. 0.95|]
|> Array.map (fun lambda ->
let num =
examplePVals
|> Array.sumBy (fun x -> if x > lambda then 1. else 0.)
let den = float examplePVals.Length * (1. - lambda)
lambda, num/den
)
let pi0EstChart =
pi0Est
|> Chart.Point
|> Chart.withYAxisStyle("",MinMax=(0.,1.))
|> Chart.withXAxisStyle("",MinMax=(0.,1.))
|> Chart.withTemplate ChartTemplates.lightMirrored
|> Chart.withXAxisStyle "$\lambda$"
|> Chart.withYAxisStyle "$\hat \pi_0(\lambda)$"
|> Chart.withMathTex(true)
|> Chart.withConfig(
Config.init(
Responsive=true,
ModeBarButtonsToAdd=[
ModeBarButton.DrawLine
ModeBarButton.DrawOpenPath
ModeBarButton.EraseShape
]
)
)
pi0EstChart
Fig 8: pi0 estimation.
The resulting diagram shows, that with increasing $\lambda$ its function value $\hat \pi_0(\lambda)$ tends to $\pi_0$. The calculation relates the actual proportion of tests greater than $\lambda$ to the proportion of $\lambda$ range the corresponding p values are in. In Storey & Tibshirani 2003 this curve is fitted with a cubic spline. A weighting of the knots by $(1 - \lambda)$ is recommended but not specified in the final publication. Afterwards the function value at $\hat \pi_0(1)$ is defined as final estimator of $\pi_0$. This is often referred to as the smoother method.
Another method (bootstrap method) (Storey et al., 2004), that does not depend on fitting is based on bootstrapping and was introduced in Storey et al. (2004). It is implemented in FSharp.Stats:
Determine the minimal $\hat \pi_0 (\lambda)$ and call it $min \hat \pi_0$ .
For each $\lambda$, bootstrap the p values (e.g. 100 times) and calculate the mean squared error (MSE) from the difference of resulting $\hat \pi_0^b$ to $min \hat \pi_0$. The minimal MSE indicates the best $\lambda$. With $\lambda$ defined, $\pi_0$ can be determined. Note: When bootstrapping an data set of size n, n elements are drawn with replacement.
In [12]:
let getpi0Bootstrap (lambda:float[]) (pValues:float[]) =
let rnd = System.Random()
let m = pValues.Length |> float
let getpi0hat lambda pVals=
let hits =
pVals
|> Array.sumBy (fun x -> if x > lambda then 1. else 0.)
hits / (m * (1. - lambda))
//calculate MSE for each lambda
let getMSE lambda =
let mse =
//generate 100 bootstrap samples of p values and calculate the MSE at given lambda
Array.init 100 (fun b ->
Array.sampleWithReplacement rnd pValues pValues.Length
|> getpi0hat lambda
)
mse
lambda
|> Array.map (fun l -> l,getMSE l)
let minimalpihat =
//FSharp.Stats.Testing.MultipleTesting.Qvalues.pi0hats [|0. .. 0.05 .. 0.96|] examplePVals |> Array.minBy snd |> snd
0.3686417749
let minpiHatShape =
Shape.init(ShapeType=ShapeType.Line,X0=0.,X1=1.,Y0=minimalpihat,Y1=minimalpihat,Line=Line.init(Dash=DrawingStyle.Dash))
let bootstrappedPi0 =
getpi0Bootstrap [|0. .. 0.05 .. 0.95|] examplePVals
|> Array.map (fun (l,x) ->
Chart.BoxPlot(data=x,orientation=Orientation.Vertical,FillColor=Color.fromHex"#1F77B4",MarkerColor=Color.fromHex"#1F77B4",Name=sprintf "%.2f" l))
|> Chart.combine
|> Chart.withShape minpiHatShape
|> Chart.withTemplate ChartTemplates.lightMirrored
|> Chart.withXAxisStyle "lambda"
|> Chart.withYAxisStyle "pi0 hat"
bootstrappedPi0
Fig 9: Bootstrapping for pi0 estimation. The dashed line indicates the minimal pi0 from Fig. 8. The bootstrapped pi0 distribution that shows the least variation to the dashed line is the optimal. In the presented example it is either 0.8 or 0.85.
For an $\lambda$, range of $\{0.0 .. 0.05 .. 0.95\}$ the bootstrapping method determines either 0.8 or 0.85 as optimal $\lambda$ and therefore $optimal \hat \pi_0$ is either $0.3703$ or $0.3686$.
The automated estimation of $\pi_0$ based on bootstrapping is implemented in FSharp.Stats.Testing.MultipleTesting.Qvalues.
In [13]:
open Testing.MultipleTesting
let pi0Stats = Qvalues.pi0BootstrapWithLambda [|0.0 .. 0.05 .. 0.95|] examplePVals
pi0Stats
0.3703327922077925
Subsequent to $\pi_0$ estimation the q values can be determined from a list of p values.
In [14]:
let qValues = Qvalues.ofPValues pi0Stats examplePVals
qValues
[ 0.2690343536429767, 0.03451771894511998, 0.260005815044248, 0.2984261021835806, 0.08590835637088742, 0.3516354103053438, 0.14017753875059466, 0.3114779827361747, 0.25753341900121823, 0.028988378992537343, 0.3259266204071664, 0.031850238633144505, 0.2934858001322298, 0.13373258389042894, 0.010485759027169157, 0.16093162128197516, 0.02086019153225808, 0.3193118083488758, 0.0744394201633433, 0.06533030596475378 ... (9836 more) ]
Variants¶
A robust variant of q value determination exists, that is more conservative for small p values when the total number of p values is low. Here the number of false positives is divided by the number of total discoveries multiplied by the FWER at the current p value. The correction takes into account the probability of a false positive being reported in the first place.
Especially when the population distributions do not follow a perfect normal distribution or the p value distribution looks strange, the usage of the robust version is recommended.
$qval = {\#FP \over \#Discoveries}$
$qval_{robust} = {\#FP \over \#Discoveries \times (1-(1-p)^m)}$
In [15]:
let qvaluesRobust =
Testing.MultipleTesting.Qvalues.ofPValuesRobust pi0Stats examplePVals
let qChart =
[
Chart.Line(Array.sortBy fst (Array.zip examplePVals qValues),Name="qValue")
Chart.Line(Array.sortBy fst (Array.zip examplePVals qvaluesRobust),Name="qValueRobust")
]
|> Chart.combine
|> Chart.withTemplate ChartTemplates.lightMirrored
|> Chart.withXAxisStyle "p value"
|> Chart.withYAxisStyle "q value"
Fig 10: Comparison of q values and robust q values, that is more conservative at low p values.
Quality plots¶
In [16]:
let pi0Line =
Shape.init(ShapeType=ShapeType.Line,X0=0.,X1=1.,Y0=pi0Stats,Y1=pi0Stats,Line=Line.init(Dash=DrawingStyle.Dash))
// relates the q value to each p value
let p2q =
Array.zip examplePVals qValues
|> Array.sortBy fst
|> Chart.Line
|> Chart.withShape pi0Line
|> Chart.withTemplate ChartTemplates.lightMirrored
|> Chart.withXAxisStyle "p value"
|> Chart.withYAxisStyle "q value"
// shows the p values distribution for an visual inspection of pi0 estimation
let pValueDistribution =
let frequencyBins = 0.025
let m = examplePVals.Length |> float
examplePVals
|> Distributions.Frequency.create frequencyBins
|> Map.toArray
|> Array.map (fun (k,c) -> k,float c / frequencyBins / m)
|> Chart.StackedColumn
|> Chart.withTraceInfo "p values"
|> Chart.withTemplate ChartTemplates.lightMirrored
|> Chart.withXAxisStyle "p value"
|> Chart.withYAxisStyle "frequency density"
|> Chart.withShape pi0Line
// shows pi0 estimation in relation to lambda
let pi0Estimation =
//Testing.MultipleTesting.Qvalues.pi0hats [|0. .. 0.05 .. 0.96|] examplePVals
[|0. .. 0.05 .. 0.95|]
|> Array.map (fun lambda ->
let num =
examplePVals
|> Array.sumBy (fun x -> if x > lambda then 1. else 0.)
let den = float examplePVals.Length * (1. - lambda)
lambda, num/den
)
|> Chart.Point
|> Chart.withTemplate ChartTemplates.lightMirrored
|> Chart.withXAxisStyle "$\lambda$"
|> Chart.withYAxisStyle "$\hat \pi_0(\lambda)$"
|> Chart.withMathTex(true)
p2q
Fig 11: p value relation to q values. At a p value of 1 the q value is equal to pi0 (black dashed line).
In [17]:
pValueDistribution
Fig 12: p value density distribution. The dashed line indicates pi0 estimated by Storeys bootstrapping method.
In [18]:
pi0Estimation
Fig 13: Visual pi0 estimation.
Definitions and Notes¶
- Benjamini-Hochberg (BH) correction is equal to q values with $\pi_0 = 1$
- Storey & Tibshirani (2003):
- "The 0.05 q-value cut-off is arbitrary, and we do not recommend that this value necessarily be used."
- "The q-value for a particular feature is the expected proportion of false positives occurring up through that feature on the list."
- "The precise definition of the q-value for a particular feature is the following. The q-value for a particular feature is the minimum false discovery rate that can be attained when calling all features up through that one on the list significant."
- "The Benjamini & Hochberg (1995) methodology also forces one to choose an acceptable FDR level before any data are seen, which is often going to be impractical."
- To improve the q value estimation if the effects are asymmetric, meaning that negative effects are stronger than positives, or vice versa a method was published in 2014 by Orr et al.. They estimate a global $m_0$ and then split the p values in two groups before calculating q values for each p value set. The applicability of this strategy however is questionable, as the number of up- and downregulated features must be equal, which is not the case in most biological experimental setups.
- The distinction of FDR and pFDR (positive FDR) is not crucial in the presented context, because in high throughput experiments with m>>100: Pr(R > 0) ~ 1 (Storey & Tibshirani, 2003, Appendix Remark A).
- The local FDR (lFDR) is sometimes referred to as the probability that for the current p value the null hypothesis is true (Storey 2011).
- If you have found typos, errors, or misleading statements, please feel free to file a pull request or contact me.
FAQ¶
Why are q values lower than their associated p values?
- q values are not necessarily greater than their associated p values. q values can maximal be pi0. The definition of p values is not the same as for q values! A q value defines what proportion of the reported discoveries may be false.
Which cut off should I use?
- "The 0.05 q-value cut-off is arbitrary, and we do not recommend that this value necessarily be used." (Storey 2003). It depends on your experimental design and the number of false positives you are willing to accept. If there are 20 discoveries, you may argue to accept if 2 of them are false positives (FDR=0.1). On the other hand, if there are 10,000 discoveries with 1,000 false positives (FDR=0.1) you may should reduce the FDR. Thereby the proportion of false positives decreases. Of course in this case the number of positives will decrease as well. It all breaks down to the matter of willingness to accept a certain number of false positives within your study. Studies, that aim to identify the presence of an specific protein of interest, the FDR should be kept low, because it inflates the risk, that this particular candidate is a false positive. If confirmatory follow up studies are cheap, you can increase the FDR, if they are expensive, you should restrict the number of false positives to avoid unpleasant discussions with your supervisor.
In my study gene RBCM has an q value of 0.03. Does that indicate, there is a 3% chance, that it is an false positive?
- No, actually the change that this particular gene is an false positive may actually be higher, because there may be genes that are much more significant than MSH2. The q value indicates, that 3% of the genes that are as or more extreme than RBCM are false positives (Storey 2003).
Should I use the default or robust version for my study?
When should I use q values over BH correction, or other multiple testing variants?
- There is no straight forward answer to this question. If you are able to define a confident pi0 estimate by eye when inspecting the p value distribution, then the q value approach may be feasible. If you struggle in defining pi0, because the p value distribution has an odd shape or there are too few p values on which you base your estimate, it is better to choose the more conservative BH correction, or even consider other methodologies.
References¶
- Storey JD, Tibshirani R, Statistical significance for genomewide studies, 2003 DOI: 10.1073/pnas.1530509100
- Storey JD, Taylor JE, Siegmund D, Strong Control, Conservative Point Estimation and Simultaneous Conservative Consistency of False Discovery Rates: A Unified Approach, 2004, http://www.jstor.org/stable/3647634.
- Storey JD, Princeton University, 2011, preprint
- Orr M, Liu P, Nettleton D, An improved method for computing q-values when the distribution of effect sizes is asymmetric, 2014, doi: 10.1093/bioinformatics/btu432
- NettletonD et al., Estimating the Number of True Null Hypotheses from a Histogram of p Values., 2006, http://www.jstor.org/stable/27595607.
- Benjamini Y, Hochberg Y, On the Adaptive Control of the False Discovery Rate in Multiple Testing With Independent Statistics, 2000, doi:10.3102/10769986025001060